Inmemory DB Cacheパターン
頻度の高いデータのキャッシュ化
目次[非表示] |
解決したい課題
データベース負荷の大部分は読み込みに関するものであることが多い。そのためデータベースからの読み込みパフォーマンスを改善すれば、システム全体のパフォーマンス向上につながる。
クラウドでの解決/パターンの説明
データベースからの読み込みパフォーマンスを向上にする方法として、頻繁に読み込まれるデータをメモリーにキャッシュするのがこのパターンである。 一度利用したデータをキャッシュしておくことで、次に使うときに(ディスクからでなく)メモリーからの読み込みで済ませる方法である。 キャッシュするデータの典型的な例としては、データベース処理において時間のかかるクエリーの結果や複雑な計算結果などが挙げられる。
実装
Azureの「RedisCache」はメモリーキャッシュサービスである。このサービスは障害時の自動復旧機能なども備わっている。 RedisCacheはmemcachedとRedisの2種類から選択が可能である。RedisはマルチAZによる高い可用性を提供し、障害時には自動的にフェイルオーバーが行われる。
- メモリーキャッシュを用意する。RedisCacheを用いてもよいし、VM上にオープンソースのmemcached・Redisを利用してもよい。
- データを読み込む際、まずメモリーキャッシュ上のデータを参照する。もしデータが無い場合はDBから読み込み、キャッシュ上に登録しておく。
構造
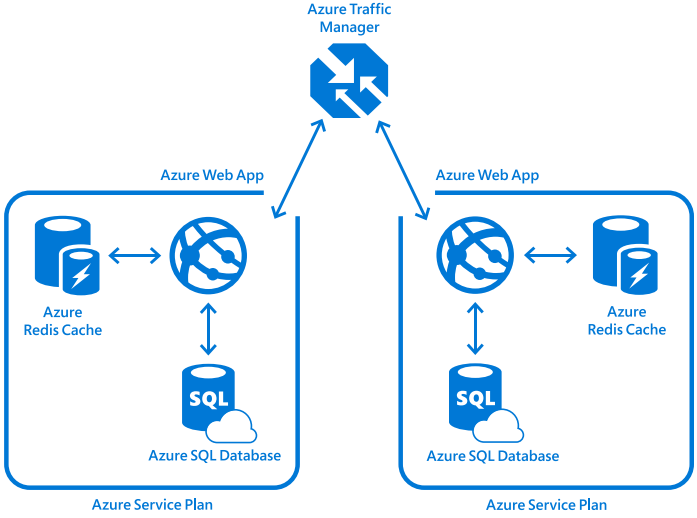
利点
- キャッシュとして高速なメモリーを用いることで、データベースの読み込み負荷を下げ、システム全体のパフォーマンスを向上できる。
- RedisCacheを用いれば、運用を効率化でき、障害にも強くなる。
注意点
- クエリーの結果をキャッシュする際、トレードオフを考える必要がある。特定のクエリーが行う読み込みと、クエリーに関連するテーブルに対する書き込みの比率が重要である。 例えば、参照を非常に頻繁に行い(毎分何回も)、更新をあまり行わない(日次、もしくは毎時程度)場合は、キャッシュする価値がある。 しかし、キャッシュに古い情報が載ったままにならないようにする工夫が必要である。
- キャッシュを利用するには、DBアクセスを行うプログラムを修正する必要がある。
その他
- 「Rename Distribution」パターンを参照。
- 「Private Cache Distribution」パターンを参照。
関連ブログ